NFS(Network File System)即网络文件系统,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
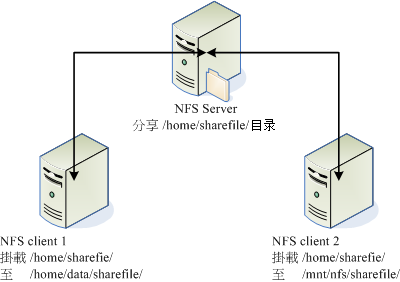
1.1 nfs为什么需要RPC?
RPC(NFS服务需要依赖RPC服务,这个比较重要) 要想了解NFS,必然要提到RPC这个服务。 因为NFS支持的功能还是比较多的,并且不同的功能都会使用不同的程序来启动。每启动一个功能就会启用一些端口来传输数据,因此NFS的功能所对应的端口才没有固定,而是采用随机取用一些未被使用的小于1024的端口来作为传输之用。但如此一来又造成客户端要连接服务器时的困扰,因为客户端要知道服务器端的相关端口才能够联机,此时我们需要远程过程调用(RPC)的服务。 RPC最主要的功能就是指定每个NFS功能所对应的端口号,并且回报给客户端,让客户端可以连接到正确的端口上。当服务器在启动NFS时会随机选用数个端口,并主动地向RPC注册。因此RPC可以知道每个端口对应的NFS功能。然后RPC固定使用端口111来监听客户端的请求并回报客户端正确的端口,所以可以让NFS的启动更为容易。 注意,启动NFS之前,要先启动RPC服务;否则NFS无法向RPC注册。另外,重新启动RPC时原本注册的数据会不见,因此RPC重新启动后它管理的所有程序都需要重新启动以重新向RPC注册,比如NFS服务。
其实,我们可以简单的理解为:NFS当作RPC服务中的一种,同时将RPC服务当作NFS服务器与NFS客户端的中间接口人,就是说NFS客户端访问NFS服务器,必须经过RPC这个接口人,才可以去访问。
1.2 NFS的工作流程
1、由程序在NFS客户端发起存取文件的请求,客户端本地的RPC(rpcbind)服务会通过网络向NFS服务端的RPC的111端口发出文件存取功能的请求。`
2、NFS服务端的RPC找到对应已注册的NFS端口,通知客户端RPC服务。
3、客户端获取正确的端口,并与NFS daemon联机存取数据。
4、存取数据成功后,返回前端访问程序,完成一次存取操作。
二、NFS服务安装配置
安装rpcbind、nfs-utils
|
|
设置开机自启动
|
|
查看当前服务状态(暂时不要启动nfs-server, 等下面固定好nfs服务端口后再启动,可以避免重启电脑)
|
|
看nfs服务向rpc注册的端口信息(当前nfs-server 没有启动,所有没有注册端口)
|
|
如果你此时启动nfs,可以发现nfs 随机注册的端口如下(暂时不要启动nfs-server, 等下面固定好nfs服务端口后再启动,可以避免重启电脑)
|
|
三、防火墙设置
NFS 的防火墙特别难设定规则,为什么呢?因为除了固定的port 111, 2049 之外, 还有很多不固定的端口是由rpc.mountd, rpc.rquotad 等服务所开启的。因此我们需要在/etc/sysconfig/nfs 指定特定的端口,这样每次启动nfs 时,相关服务启动的端口就会固定,如此一来, 我们就能够设定正确的防火墙了!
3.1 固定nfs服务端口
固定端口nfs 2049、portmapper111 ,另外3个服务端口可设置为mountd 892、rpc.statd 662、 nlockmgr 32803、32769
具体配置:
1.修改/etc/sysconfig/nfs文件,将下列内容的注释去掉,如果没有则添加:
|
|
2. vim /etc/modprobe.d/lockd.conf
|
|
固定之后,启动nfs-server服务,后执行rpcinfo -p命令,查看nfs向rpc注册的端口
(如果你已经启动过nfs-server服务,则光重启NFS服务不能解决问题,需要重启电脑,才能将端口固定)
|
|
3.2 配置防火墙:
编辑firewalld中nfs服务的配置文件:
|
|
将刚才固定的那几个端口加入配置文件:
|
|
开启nfs
|
|
四、挂载
4.1 exports文件配置格式
|
|
说明:
NFS共享目录:
|
|
NFS客户端地址:
|
|
参数:
| 参数值 | 内容说明 |
|---|---|
| rw ro | 该目录分享的权限是可擦写(read-write) 或只读(read-only),但最终能不能读写,还是与文件系统的rwx 及身份有关。 |
| sync async | sync 代表数据会同步写入到内存与硬盘中,async 则代表数据会先暂存于内存当中,而非直接写入硬盘! |
| no_root_squash root_squash | 客户端使用NFS 文件系统的账号若为 root 时,系统该如何判断这个账号的身份?预设的情况下,客户端root 的身份会由root_squash 的设定压缩成nfsnobody, 如此对服务器的系统会较有保障。但如果你想要开放客户端使用root 身份来操作服务器的文件系统,那么这里就得要开 no_root_squash 才行! |
| all_squash | 不论登入NFS 的使用者身份为何, 他的身份都会被压缩成为匿名用户,通常也就是 nobody(nfsnobody) 啦! |
| anonuid anongid | anon 意指anonymous (匿名者) 前面关于*_squash 提到的匿名用户的UID 设定值,通常为nobody(nfsnobody),但是你可以自行设定这个UID 的值!当然,这个UID 必需要存在于你的/etc/passwd 当中!anonuid 指的是UID 而anongid 则是群组的GID 啰。 |
4.2 Server创建nfs共享
假如uid=1001 gid=1001是应用用户
|
|
重新加载nfs配置
|
|
客户端查看nfs服务器挂载情况
|
|
4.3 Client端挂载
挂载测试
|
|
写入fstab
|
|
因为ID不一致的问题 建议Client端新建相同uid和gid的用户
五、autofs实现自动挂载
参考:autofs
5.1 客户端安装autofs
|
|
5.2 挂载为本地的非一级目录
将192.168.0.103:/data目录挂载到192.168.0.104的/dir1/dir2目录
查看服务端共享
|
|
修改客户端vim /etc/auto.master,添加以下内容, 意思是系统访问dir1下面的文件的时候,去/etc/auto.nfs 去查找nfs的配置
|
|
/etc/auto.nfs 内容如下,文件需要新建
|
|
5.3 挂载位本地的一级目录
修改客户端vim /etc/auto.master,添加以下内容,
|
|
/etc/auto.nfs 内容如下,文件需要新建
|
|
五、常见错误
1 . 在CentOS7服务器上配置NFS服务并共享出目录后,发现客户端不能Mount共享出的目录,错误提示:
|
|
关闭服务器端的防火墙后,问题解决,说明是防火墙端口的问题。
2 client端无法读写
- 确保nfs-server /etc/exports中开启了rw
- 确保client端映射到server端的用户对于server端的目录有读写权限(涉及到uid,gid是否被压缩)
- 确保client端挂载参数包含rw
参考
CHAPTER 8. NETWORK FILE SYSTEM (NFS)
https://www.howtoforge.com/tutorial/setting-up-an-nfs-server-and-client-on-centos-7/
]]>